publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026

2025



2024
-
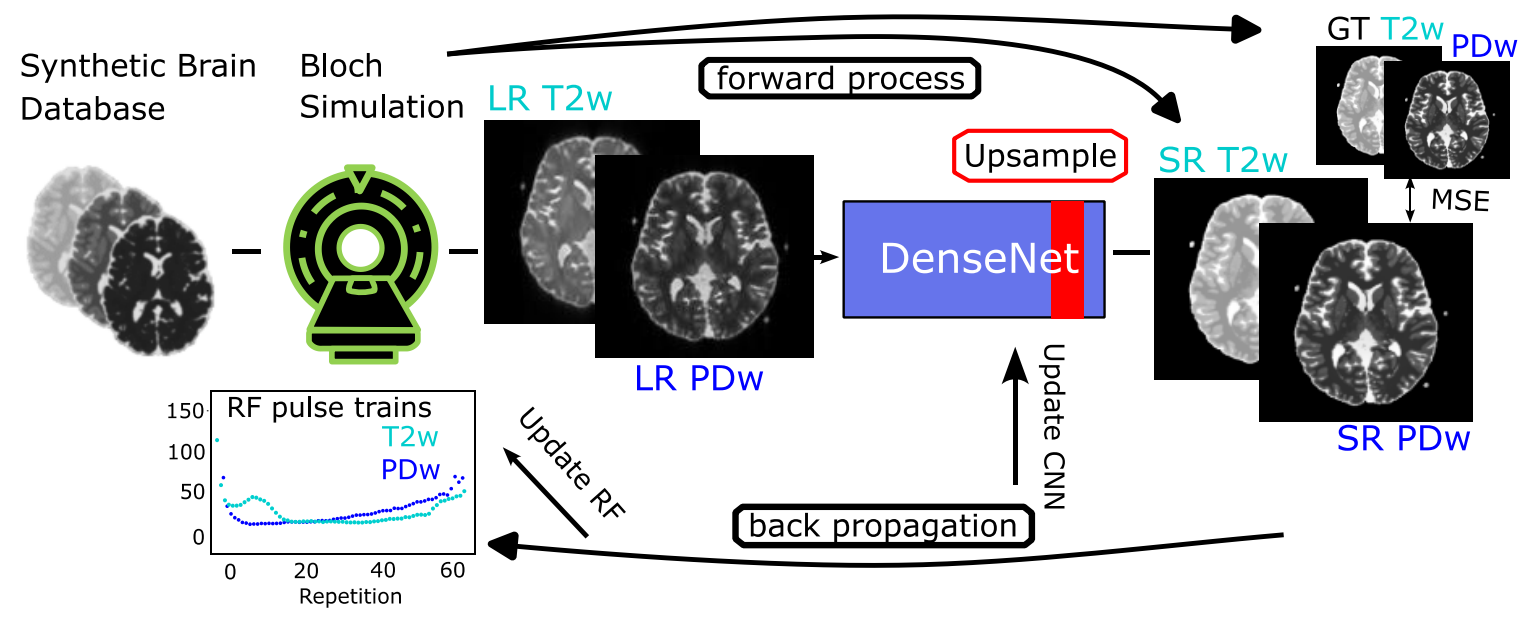 Joint MR sequence optimization beats pure neural network approaches for spin-echo MRI super-resolutionIn International Society for Magnetic Resonance in Medicine (ISMRM) Annual Meeting, 2024
Joint MR sequence optimization beats pure neural network approaches for spin-echo MRI super-resolutionIn International Society for Magnetic Resonance in Medicine (ISMRM) Annual Meeting, 2024


2023
-
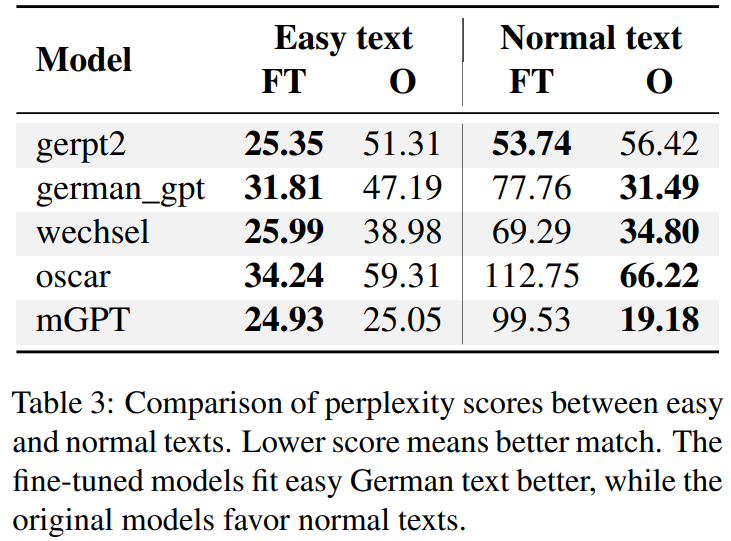 Language Models for German Text Simplification: Overcoming Parallel Data Scarcity through Style-specific Pre-trainingIn Findings of the Association for Computational Linguistics: ACL 2023, 2023
Language Models for German Text Simplification: Overcoming Parallel Data Scarcity through Style-specific Pre-trainingIn Findings of the Association for Computational Linguistics: ACL 2023, 2023 -
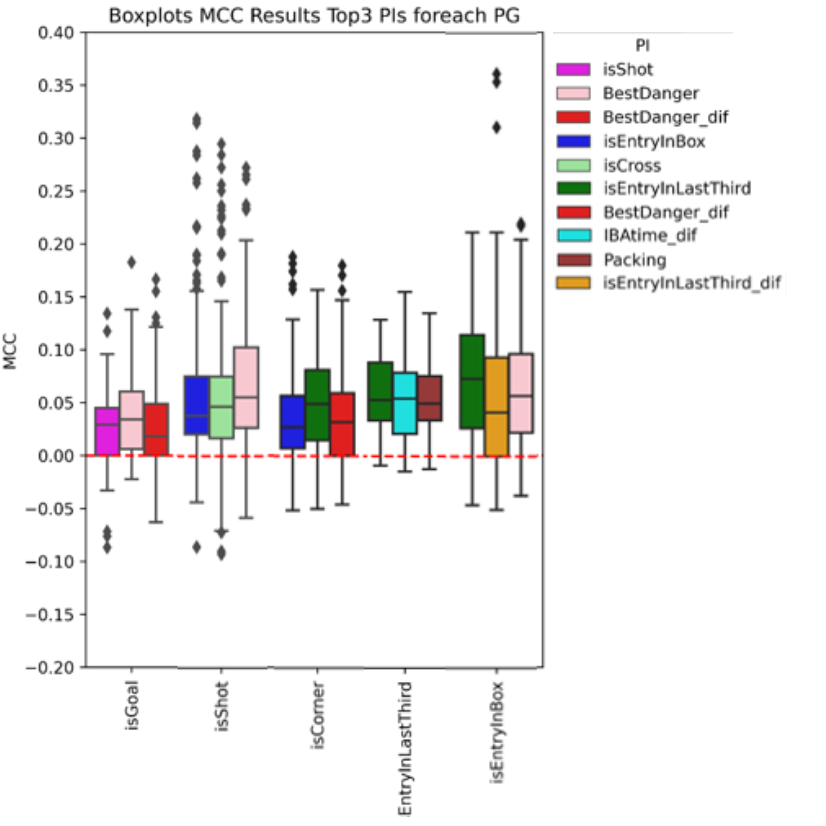 Which Indicators Matter? Using Performance Indicators to Predict In-Game Success-Related Events in Association FootballIn Issue 2/2025 of the International Journal of Computer Science in Sport, 2023First presented in 2023. Published 2025 in IJCSS. Young Researcher Award at 28. Annual Conference of the Commission on Soccer of the German Association for Sports Science (dvs), 2023.
Which Indicators Matter? Using Performance Indicators to Predict In-Game Success-Related Events in Association FootballIn Issue 2/2025 of the International Journal of Computer Science in Sport, 2023First presented in 2023. Published 2025 in IJCSS. Young Researcher Award at 28. Annual Conference of the Commission on Soccer of the German Association for Sports Science (dvs), 2023.


